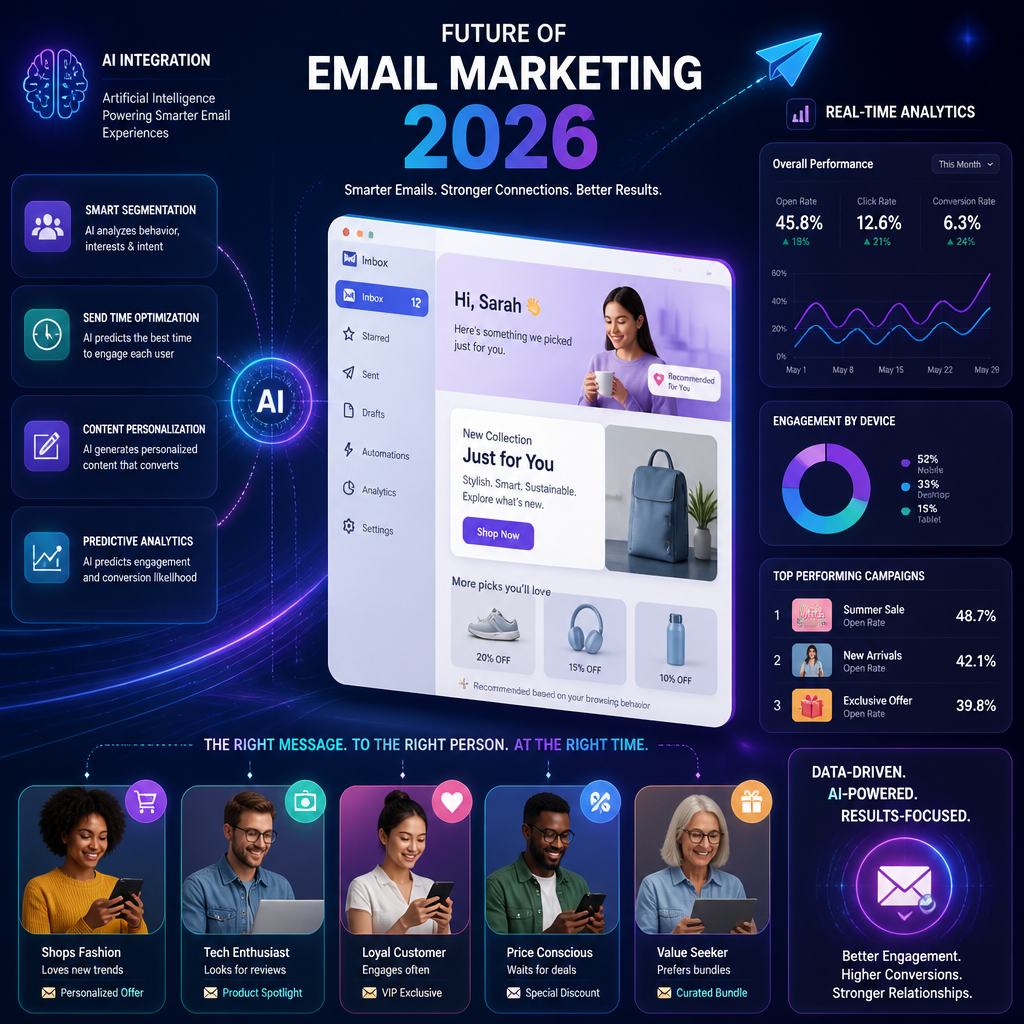
Explore the upcoming trends and strategies shaping email marketing in 2026.

Introduction to Email Marketing Trends
Email marketing trends for 2026 aren’t about chasing shiny tactics. They’re about doing the fundamentals at a higher level because inboxes are crowded and patience is low.
Here’s the real shift I’m watching: your “average” email program won’t survive on averages anymore. Average open rates. Average click rates. Average segmentation (aka none). Average design (heavy images, slow load, tiny text). If you’re competing with brands that tailor content, send based on behavior, and test like they mean it, you’ll feel it.
A quick QA-flavored story: I once tested a “simple” promotional campaign where the marketing team swore the segmentation was correct—VIP customers would get early access, everyone else would get general access. In staging it looked fine. In production, a single boolean field was inverted (classic), and we gave general subscribers the VIP offer first. Cue: angry emails from actual VIPs, support tickets, and a rushed follow-up that performed even worse. That wasn’t a “creative” failure. It was a systems + process failure.
So when I talk about trends, I’m going to keep coming back to:
- Data discipline (because personalization and automation are only as good as the inputs)
- Real testing (not “send yourself a test email and glance at it on iPhone”)
- Consent and trust (because over-personalization can backfire fast)
Step-by-step: how I’d “trend-proof” an email program in 30 days
If I were dropped into a small team today and told to prep for 2026, I’d do this in order:
- Audit list sources + consent: where subscribers came from, what they agreed to, and whether you can prove it.
- Fix the top 10 template breakpoints: Gmail mobile, iOS Mail, Outlook desktop (yes, still), dark mode.
- Define 5–8 core segments: new subscribers, active buyers, lapsed buyers, high AOV, category interest, etc.
- Stand up 3 automations that pay for themselves: welcome, abandonment/browse, post-purchase.
- Add measurement that answers business questions: revenue per email, revenue per subscriber, and churn/unsub by campaign type.
If you do only that, you’re already aligned with the biggest trends—because most “future” email wins are just better execution of the boring stuff.
The Rise of Personalization in Email Marketing
Personalization is the trend everyone talks about, and in 2026 it’ll be the baseline—not the differentiator.
The proof point marketers love is still true: according to the State of Personalization Report by Twilio, emails with personalized subject lines are 26% more likely to be opened compared to those without. But subject lines are the smallest part of the story.
What’s changing is what people consider “creepy” vs “helpful.” “Hey Mariaa, we saw you looking at red sneakers at 2:14 AM” is… a lot. “Still looking for running shoes? Here are the models that fit your size and budget” feels useful.
What personalization that actually works looks like
In practice, the best-performing personalization I’ve seen is built on a few predictable inputs:
- Lifecycle stage (new subscriber vs repeat buyer vs churn-risk)
- Behavior (browse, add-to-cart, category clicks, time since last purchase)
- Preference (explicit choices beat inferred guesses)
- Context (seasonality, location, inventory, pricing)
Brands like Amazon and Spotify are the obvious examples because they have the data and the muscle. Amazon’s recommendations are basically a product merchandising machine disguised as “helpful suggestions.” Spotify’s “Wrapped” style experiences and taste-based recommendations keep engagement high because they reflect the user back to themselves.
My take: AI and machine learning will keep pushing this forward, but the winners won’t be the brands with the fanciest models—they’ll be the ones with the cleanest data and the best restraint.
Step-by-step: a safe personalization ladder (so you don’t faceplant)
If your team is early, climb in levels:
- Level 1 — Identity: first name (only if you know the field isn’t garbage), location/timezone.
- Level 2 — Behavior blocks: “Because you bought X,” “Because you read Y,” “Recommended for you.”
- Level 3 — Dynamic offers: category-specific discounts, bundles, replenishment reminders.
- Level 4 — Predictive timing: send-time optimization, frequency caps per user.
- Level 5 — Journey branching: content changes based on actions inside the sequence.
You’ll notice I didn’t mention “hyper-personalized everything.” That’s because most teams don’t have the instrumentation to validate it.
Common mistakes I keep seeing (and how to avoid them)
- Bad merge fields: “Hi ,” or “Hi FNAME.” It screams amateur hour. In QA I always insist on fallbacks (e.g., “Hi there,”).
- Over-segmentation: 40 tiny segments that never get enough volume to learn anything.
- Personalization without consent: you can comply with the law and still feel invasive. Watch unsubscribes and spam complaints when you add new data-driven blocks.
- Stale recommendations: showing out-of-stock products or stuff the customer already returned. That’s a trust killer.
The 2026 version of personalization is less about impressing people and more about quiet relevance—the email feels like it belongs in their inbox.
Email Automation: Efficiency and Effectiveness
Automation in 2026 isn’t optional—manual sending doesn’t scale, and it’s too slow to react to behavior.
The business case is clear: according to data from HubSpot, businesses that automate their marketing see conversion rates increase by over 50% on average. I don’t treat that as a promise, but I do treat it as a sign that most manual programs are leaving money on the table.
The automations that tend to matter most
You already listed the classics, and yes, they still dominate:
- Welcome sequences
- Cart abandonment emails
- Re-engagement campaigns
But in 2026, the teams doing well are adding a few more “unsexy” automations:
- Post-purchase education (reduces refunds, increases repeat purchases)
- Back-in-stock + price-drop alerts (high intent, low effort)
- Review/NPS requests timed to product delivery (timing beats copy)
Platforms like Mailchimp and Klaviyo make this easier than it used to be. The hard part is not clicking around in the automation builder—it’s deciding the rules and making sure they’re correct.
A real example: the automation bug that tanked a week
I’ve seen a cart abandonment flow that fired correctly… and then fired again every time the user revisited the cart, even after purchase. The trigger logic was “Cart Updated” instead of “Checkout Started,” and the exit condition was missing. People who already bought got “Your cart is waiting” emails for days. Unsubscribes spiked, support got hammered, and deliverability took a hit.
That’s why I treat email automation like software. Because it is.
Step-by-step: how I QA an automation before it hits production
Here’s the checklist I use (lightweight, but it catches the big failures):
- Map the flow on paper first: triggers, delays, branches, exit rules.
- Create test profiles for each path (new buyer, repeat buyer, discount used, etc.).
- Validate entry conditions: what exact event starts the flow?
- Validate exit conditions: what removes someone immediately?
- Check frequency caps: what prevents stacking multiple flows?
- Test real rendering: Gmail + iOS + Outlook; dark mode.
- Verify tracking: UTM parameters, conversion events, revenue attribution.
- Run a 24–48 hour soft launch to a small segment.
Common automation mistakes (they’re predictable)
- No suppression logic (customers get promo emails inside onboarding)
- No “cooldown” periods (people get three emails in one day from different flows)
- Set-and-forget content (old pricing, expired offers)
In 2026, automation winners will be the teams who treat flows as living products: reviewed monthly, measured, tweaked.
Emerging Technologies Influencing Email Marketing
“Emerging tech” can get hand-wavy fast, so I’m going to be picky. The stuff that will actually affect your email program by 2026 falls into a few buckets.
AI + analytics: less guessing, more measurable relevance
AI is already being used for:
- Predicting what a subscriber is likely to buy next
- Choosing the best time to send (per user)
- Generating subject line variants
- Clustering audiences based on behavior
My bias: AI is best used as an assistant, not the driver. I’ve seen AI-written copy that reads fine but doesn’t match the brand voice, and it can quietly increase spam complaints because it feels generic.
How I know: I’ve QA’d campaigns where the “AI subject line” beat the control on opens, then lost on clicks and revenue because it overpromised.
Blockchain: potentially useful, but don’t plan your roadmap around it
Blockchain comes up because trust and authenticity matter more every year. According to Forbes, blockchain can help verify the authenticity of emails, reducing fraud and improving trust among consumers.
Do I think most marketing teams will be “doing blockchain email” in 2026? Probably not. But I do think the idea behind it—verifiable identity and reduced fraud—will keep shaping email standards and vendor tooling.
Chatbots + email: tighter handoff between inbox and conversation
The practical use case I see is this:
- Email drives someone to an action (book, buy, ask a question)
- A chatbot handles the first layer of support/sales
- The email platform captures the outcome and adjusts the next message
That loop—email → conversation → data → better email—is where the value is.
Step-by-step: a simple “emerging tech” pilot that won’t derail you
If you want to experiment without wrecking your calendar:
- Pick one flow (welcome or post-purchase is safest).
- Add one AI element (send-time optimization or product recommendations).
- Define success as revenue per recipient (not just opens).
- Run A/B for 2–4 weeks.
- Keep a manual override. Always.
Common mistakes with new tech
- Optimizing the wrong metric (open rate goes up, revenue goes down)
- Adding complexity before data hygiene (garbage in, garbage out)
- Trusting black-box outputs without sampling real user experiences
By 2026, tech will matter—but execution and judgment will matter more.
Trends in Email Content and Design
Your 2026 email design trend is simple: it has to work on mobile, instantly, without drama.
You mentioned a stat that I’ve seen reflected in real programs: over 70% of emails are opened on mobile devices. Even when desktop revenue is higher, mobile is where people decide if they’ll deal with you at all.
What I expect to keep growing
- Mobile-first layouts: single column, readable type, tappable buttons
- Immersive content: short video snippets, GIFs (used carefully)
- Bold typography and colors: not “loud,” just clear and scannable
- Interactivity: polls, surveys, preference centers—anything that earns a click
One caveat from the trenches: interactive elements can break in certain clients. That means you design it like progressive enhancement—nice-to-have, not required-to-function.
A real example: the “beautiful” email that didn’t load
I tested a holiday campaign once that looked like a landing page—big hero images, custom fonts, multiple product grids. On fast Wi‑Fi, it was gorgeous. On mobile data, it loaded in chunks and the CTA was below the fold for several seconds.
Result: complaints like “your email is blank,” and the click rate was half of the plainer template.
Design doesn’t get credit for being pretty. It gets credit for driving action.
Best Practices for Designing Emails (the stuff I enforce)
- Subject line + preheader as a pair: don’t waste the preheader on “View in browser.”
- Tap targets: buttons should be easy to hit with a thumb.
- Dark mode checks: especially for logos and text over images.
- Alt text that’s not useless: describe the offer, not “image1.”
- Keep weight reasonable: compress images; avoid huge GIFs.
Step-by-step: my quick design QA pass (15 minutes)
- Open in Gmail app (Android or iOS): scanability, CTA visibility.
- Open in iOS Mail: dark mode, image scaling.
- Open in Outlook desktop: spacing, font fallbacks, table weirdness.
- Turn images off (where possible): does the email still make sense?
- Click every link: correct destination, correct UTM parameters.
Common design mistakes in 2026-ready programs
- Tiny text (especially in product grids)
- CTA buttons too close together (fat-finger city)
- One giant image (breaks, clips, and feels spammy)
If you want one rule: design for the most impatient person on the oldest client you still care about.
FAQ Section on Email Marketing Trends
-
What are the major trends in email marketing for 2026?
Personalization (done with restraint), automation with better suppression/frequency control, and smarter use of AI-driven analytics. Also: mobile-first design isn’t a trend anymore—it’s the minimum. -
How will personalization impact email marketing in 2026?
Personalization will raise the bar for relevance. Per Twilio’s report, personalized subject lines are 26% more likely to be opened (State of Personalization Report by Twilio). The bigger impact comes from personalized content blocks and lifecycle-based journeys. -
What role does automation play in email marketing strategies?
Automation runs the money flows (welcome, abandonment, post-purchase) and prevents teams from relying on manual blasts. HubSpot reports businesses that automate marketing see conversion rates increase by over 50% on average (HubSpot). -
What technologies will shape the future of email marketing?
AI/ML for recommendations and timing, better analytics, and improved identity/trust approaches. On the trust side, Forbes notes blockchain’s potential to verify email authenticity and reduce fraud. -
How can businesses prepare for the future of email marketing?
Start with fundamentals: clean segmentation, reliable automations, mobile-first templates, and a testing process. Then pilot one “new” capability at a time (send-time optimization or recommendations), and measure revenue—not vanity metrics. -
Are there any risks associated with email marketing in the future?
Yes: privacy backlash, consent issues, and deliverability damage from over-sending or broken automations. A lot of risk comes from moving fast without QA—wrong segments, missing suppression, and stale dynamic content.
Conclusion and Key Takeaways
By 2026, the email programs that win won’t be the loudest. They’ll be the most controlled.
- Personalization will be expected, but it has to feel helpful—not invasive—and it must be backed by clean data.
- Automation will keep compounding results, but only if you build it with real triggers, exit rules, and frequency caps.
- Emerging tech (AI especially) will help, but it won’t save a messy program. Use it as a multiplier on good fundamentals.
- Content and design will be judged on speed, clarity, and mobile usability—not aesthetics.
If you want a practical next step, pick one section and operationalize it this week: build (or fix) your welcome sequence, add two meaningful segments, or do a full QA pass on your highest-traffic automation.
And if you’re collecting resources for what to watch next, keep these handy: The Future of Email Marketing: Key Trends to Watch in 2026 and (oddly useful for thinking about attention + devices) Smartwatch Features for 2026.